Mempelajari Secara Singkat Hadoop : Data Flow in Map Reduce
Data Flow In MapReduce
MapReduce digunakan untuk memproses sejumlah besar data. Untuk menangani data yang datang secara paralel dan terdistribusi, data harus mengalir melalui berbagai fase.
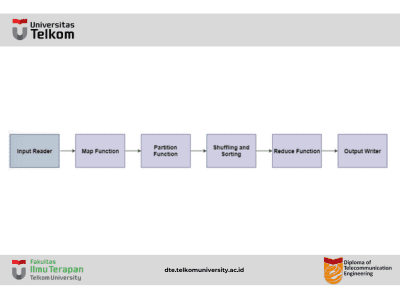
Fase Aliran Data MapReduce
- Input Reader Input reader membaca data yang masuk dan membaginya menjadi blok data dengan ukuran yang sesuai (64 MB hingga 128 MB). Setiap blok data dihubungkan dengan fungsi Map.Setelah input reader membaca data, input reader menghasilkan pasangan kunci-nilai yang sesuai. File input berada di HDFS.
- Fungsi Map Fungsi map memproses pasangan kunci-nilai yang masuk dan menghasilkan pasangan kunci-nilai keluaran yang sesuai. Jenis input dan output fungsi map mungkin berbeda satu sama lain.
- Fungsi Partisi Fungsi partisi menugaskan keluaran dari setiap fungsi Map ke reducer yang sesuai. Fungsi ini menggunakan kunci dan nilai yang tersedia dan mengembalikan indeks dari reducer.
- Pengacakan dan Penyortiran Data diacak antara/dalam node sehingga bisa berpindah dari map dan siap untuk diproses oleh fungsi reduce. Kadang-kadang, pengacakan data dapat memakan waktu komputasi yang cukup lama.Operasi penyortiran dilakukan pada data input untuk fungsi reduce. Di sini, data dibandingkan menggunakan fungsi perbandingan dan diatur dalam bentuk yang terurut.
- Fungsi Reduce Fungsi reduce ditugaskan ke setiap kunci unik. Kunci-kunci ini sudah diatur dalam urutan yang terurut. Nilai yang terkait dengan kunci dapat diiterasi oleh fungsi reduce dan menghasilkan keluaran yang sesuai.
- Output Writer Setelah data mengalir dari semua fase di atas, output writer dieksekusi. Peran output writer adalah menulis keluaran reduce ke penyimpanan yang stabil.