")
Hai Google, Halo Siri: Bagaimana Asisten Suara di Ponsel ‘Mengerti’ Perintah Kita? (Sebuah Keajaiban Kecerdasan Buatan yang Terhubung ke Server Pintar di ‘Awan’)
“Hai Google, apa cuaca hari ini?” “Halo Siri, putar lagu favoritku.” “Alexa, tambahkan susu ke daftar belanja.”
Kalimat-kalimat seperti ini sudah menjadi bagian dari interaksi sehari-hari kita dengan teknologi. Asisten suara di smartphone, smart speaker, atau perangkat lain seolah mengerti apa yang kita ucapkan dan mampu merespons dengan relevan. Terkadang, kemampuannya terasa seperti sihir. Bagaimana mungkin sebuah perangkat bisa “mendengar”, “memahami”, dan “menjawab” layaknya manusia?
Jawabannya tentu bukan sihir, melainkan sebuah orkestrasi teknologi canggih yang melibatkan berbagai cabang Kecerdasan Buatan (AI), pemrosesan bahasa alami, dan yang tak kalah penting, koneksi konstan ke server-server super pintar yang berada di “awan” (cloud).
Langkah Pertama: Mendengarkan dan Mengubah Suara Menjadi Teks (Automatic Speech Recognition – ASR)
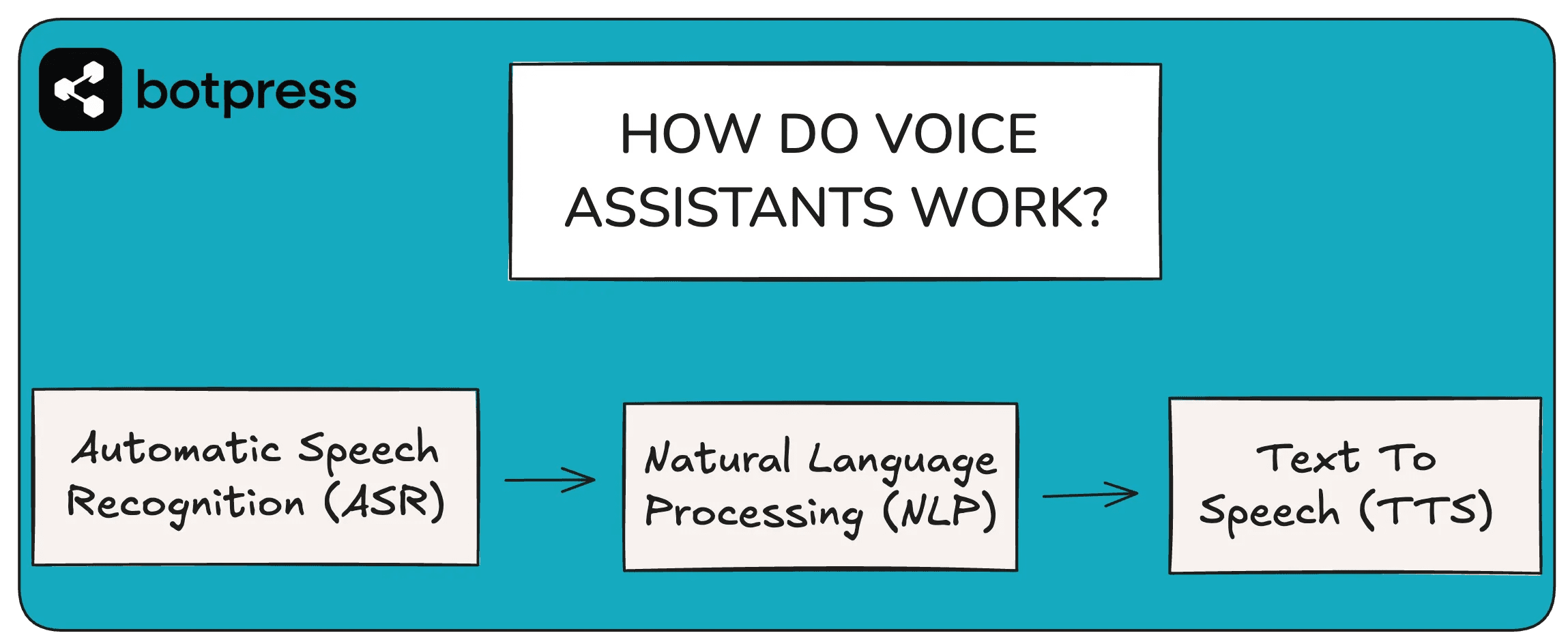
Semua dimulai ketika Anda mengucapkan perintah.
- Deteksi “Kata Pembangun” (Wake Word): Sebelum asisten suara benar-benar “mendengarkan” perintah lengkap Anda, ia harus “bangun” terlebih dahulu. Inilah fungsi dari frasa seperti “Hai Google”, “Halo Siri”, atau “Alexa”. Perangkat Anda memiliki chip khusus berdaya rendah yang terus menerus mendengarkan pola suara spesifik ini. Proses pendeteksian wake word ini biasanya terjadi secara lokal di perangkat Anda untuk menjaga privasi dan memastikan respons yang cepat.
- Menangkap dan Menganalisis Gelombang Suara: Setelah wake word terdeteksi, mikrofon di perangkat Anda akan aktif merekam apa yang Anda ucapkan selanjutnya. Gelombang suara Anda diubah menjadi sinyal digital.
- Proses ASR: Sinyal digital ini kemudian diproses oleh sistem Automatic Speech Recognition (ASR).
- Pemecahan Suara: ASR memecah rekaman suara Anda menjadi unit-unit suara terkecil yang disebut fonem (misalnya, bunyi /b/, /u/, /d/, /i/ untuk kata “budi”).
- Pencocokan dengan Model Bahasa: Sistem ASR kemudian mencocokkan urutan fonem ini dengan model akustik dan model bahasa yang sangat besar. Model bahasa ini berisi jutaan kata dan frasa, serta probabilitas bagaimana kata-kata tersebut biasanya dirangkai dalam percakapan.
- Transkripsi ke Teks: Hasil akhirnya adalah transkripsi teks dari ucapan Anda. Misalnya, ucapan “Cuaca hari ini” diubah menjadi teks “Cuaca hari ini”.
Proses ASR ini sangat kompleks dan seringkali dibantu oleh server di cloud untuk akurasi yang lebih tinggi, terutama jika Anda menggunakan bahasa yang rumit, memiliki aksen tertentu, atau berbicara di lingkungan yang bising. Tantangan bagi ASR termasuk mengenali berbagai aksen, kecepatan bicara, kebisingan latar belakang, dan ambiguitas kata yang bunyinya mirip tetapi artinya berbeda.
Langkah Kedua: Memahami Maksud di Balik Teks (Natural Language Understanding – NLU)
Setelah ucapan Anda berhasil diubah menjadi teks, “otak” sebenarnya dari asisten suara mulai bekerja. Teks transkripsi ini dikirimkan (biasanya melalui internet) ke server di cloud untuk diproses oleh sistem Natural Language Understanding (NLU). Inilah inti dari bagaimana asisten suara “mengerti” perintah Anda.
Proses NLU melibatkan beberapa tahapan analisis:
- Analisis Sintaksis (Struktur Kalimat): NLU mencoba memahami tata bahasa dan struktur kalimat Anda – mana subjek, predikat, objek, dan keterangan lainnya.
- Analisis Semantik (Makna Kata): Sistem ini berusaha memahami makna dari setiap kata dan bagaimana kata-kata tersebut berhubungan satu sama lain dalam konteks kalimat.
- Identifikasi Entitas (Entity Recognition): NLU akan mengenali dan mengekstrak elemen-elemen penting atau “entitas” dalam perintah Anda. Entitas ini bisa berupa:
- Nama orang (misalnya, “Ibu”, “Budi”)
- Lokasi (misalnya, “Jakarta”, “kantor”)
- Waktu dan Tanggal (misalnya, “besok jam 7 pagi”, “hari ini”)
- Nama aplikasi atau layanan (misalnya, “Spotify”, “WhatsApp”, “Kalender”)
- Nama objek (misalnya, “lagu Bohemian Rhapsody”, “susu”)
- Identifikasi Maksud (Intent Recognition): Ini adalah bagian paling krusial. NLU menentukan apa sebenarnya tujuan atau “maksud” dari perintah Anda. Apakah Anda ingin:
- Mencari informasi? (“Siapa penemu telepon?”)
- Memutar musik? (“Putar playlist favoritku”)
- Mengatur alarm atau pengingat? (“Ingatkan aku rapat jam 2 siang”)
- Mengirim pesan? (“Kirim pesan ke Ayah bilang aku akan terlambat”)
- Mengontrol perangkat lain? (“Nyalakan lampu kamar”)
- Pengelolaan Dialog (Dialog Management): Untuk percakapan yang lebih kompleks atau multi-giliran, sistem NLU (bersama komponen lain) akan mencoba mengingat konteks dari percakapan sebelumnya agar responsnya lebih relevan dan tidak terasa seperti memulai dari awal setiap kali.
Sebagai contoh, jika Anda berkata, “Hai Google, putar lagu ‘Pelangi’ oleh HIVI! di Spotify,” sistem NLU akan menguraikannya menjadi:
- Maksud: Putar Musik
- Entitas: Judul Lagu=”Pelangi”, Artis=”HIVI!”, Aplikasi=”Spotify”
Teknologi Machine Learning (Pembelajaran Mesin) dan Deep Learning (Pembelajaran Mendalam) memainkan peran sangat besar dalam NLU. Model-model AI ini dilatih menggunakan miliaran contoh kalimat dan percakapan manusia agar bisa memahami berbagai variasi bahasa, slang, dan konteks.
Langkah Ketiga: Menemukan Jawaban atau Melakukan Tindakan (Action & Information Retrieval)
Setelah NLU berhasil memahami maksud dan entitas dari perintah Anda, sistem asisten suara akan mengambil langkah berikutnya:
- Jika Perintahnya Mencari Informasi: Asisten akan mengakses basis data atau knowledge graph yang sangat besar. Knowledge graph ini adalah jaringan informasi terstruktur tentang berbagai entitas (orang, tempat, benda, konsep) dan hubungan antar entitas tersebut, yang seringkali dimiliki dan dikelola oleh perusahaan teknologi besar seperti Google atau Apple di server cloud mereka.
- Jika Perintahnya Melakukan Tindakan: Asisten akan berinteraksi dengan aplikasi atau layanan lain yang relevan. Ini biasanya dilakukan melalui API (Application Programming Interface) – semacam “jembatan” perangkat lunak yang memungkinkan berbagai program berkomunikasi satu sama lain. Misalnya, untuk memutar musik di Spotify, asisten akan mengirim perintah ke API Spotify. Untuk mengirim pesan WhatsApp, ia akan berinteraksi dengan API WhatsApp.
- Jika Perintahnya Terkait Fungsi Internal Perangkat: Seperti menyalakan Wi-Fi, Bluetooth, atau mengatur volume, asisten akan langsung mengontrol fungsi tersebut di perangkat Anda.
Langkah Keempat: Menyampaikan Jawaban atau Konfirmasi (Natural Language Generation – NLG & Text-to-Speech – TTS)
Setelah informasi ditemukan atau tindakan berhasil dilakukan (atau gagal), asisten suara perlu memberitahu Anda.
- Natural Language Generation (NLG): Jawaban atau status dari tindakan tersebut (yang mungkin masih berupa data mentah atau kode) kemudian diolah oleh sistem Natural Language Generation (NLG). Sistem NLG, yang juga sering berjalan di cloud, bertugas menyusun respons dalam bentuk kalimat teks yang terdengar alami, koheren, dan sopan, seolah-olah diucapkan oleh manusia. Misalnya, daripada hanya menampilkan “Status alarm: aktif, waktu: 06:00”, NLG akan mengubahnya menjadi kalimat seperti, “Baik, alarm sudah disetel untuk jam 6 pagi.”
- Text-to-Speech (TTS): Terakhir, teks yang dihasilkan oleh NLG diubah kembali menjadi suara oleh mesin Text-to-Speech (TTS). Model TTS modern menggunakan teknik AI canggih untuk menghasilkan suara yang tidak lagi terdengar kaku seperti robot, melainkan memiliki intonasi, penekanan, dan bahkan emosi yang lebih natural. Suara inilah yang kemudian Anda dengar melalui speaker perangkat Anda.
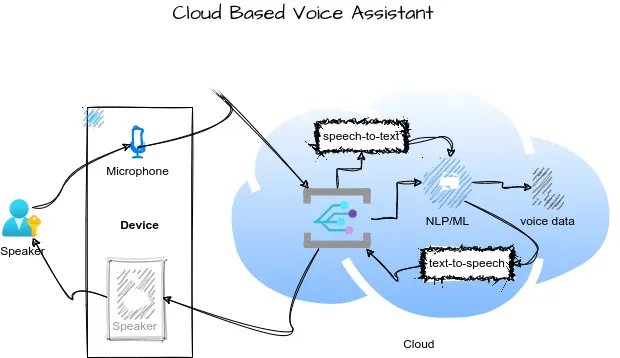
Peran Vital Server Pintar di ‘Awan’ (Cloud Computing)

{kind=link}
{kind=link}
Dari penjelasan di atas, jelas bahwa sebagian besar “kecerdasan” asisten suara tidak berada di dalam ponsel Anda, melainkan di server-server super komputer yang berlokasi di pusat data (data centers) di seluruh dunia – atau yang biasa kita sebut “awan” (cloud).
- Kekuatan Pemrosesan Masif: Ponsel kita, meskipun canggih, tidak memiliki daya komputasi yang cukup untuk melakukan analisis ASR, NLU, dan NLG yang sangat kompleks, serta mengakses dan memproses knowledge graph raksasa secara instan. Semua ini membutuhkan ribuan server yang bekerja secara paralel di cloud.
- Basis Data dan Model AI yang Selalu Terbarui: Kamus bahasa, model akustik, knowledge graph, dan algoritma AI yang digunakan oleh asisten suara terus menerus diperbarui dan disempurnakan oleh para ilmuwan dan insinyur di perusahaan teknologi. Semua pembaruan “kecerdasan” ini terjadi di cloud, sehingga asisten suara Anda menjadi semakin pintar dari waktu ke waktu tanpa Anda perlu sering-sering mengupdate aplikasinya secara manual untuk peningkatan inti AI.
- Skalabilitas: Infrastruktur cloud dirancang untuk bisa melayani jutaan, bahkan miliaran, permintaan dari pengguna asisten suara di seluruh dunia secara bersamaan dan responsif.
- Personalisasi: Dengan izin pengguna, data interaksi Anda dengan asisten suara dapat digunakan di cloud untuk melatih model AI agar lebih memahami preferensi, gaya bicara, dan konteks spesifik Anda, sehingga memberikan pengalaman yang lebih personal.
- Pembelajaran Berkelanjutan: Setiap interaksi, terutama ketika pengguna mengoreksi kesalahan pemahaman asisten atau memberikan umpan balik, bisa menjadi data pelatihan baru yang berharga untuk terus menyempurnakan model AI di cloud.
Mengapa Kadang Asisten Suara Salah Paham?
Meskipun sudah sangat canggih, asisten suara belum sempurna. Beberapa alasan mengapa ia kadang salah mengerti:
- Kualitas mikrofon perangkat Anda atau adanya kebisingan latar belakang yang parah.
- Aksen, dialek, atau cara bicara yang tidak umum bagi model AI yang dilatih.
- Ambiguitas dalam bahasa manusia (satu kata bisa punya banyak arti).
- Keterbatasan model AI itu sendiri – mereka belum memiliki pemahaman dunia dan konteks seluas manusia.
- Kurangnya informasi kontekstual yang spesifik untuk permintaan Anda.
Masa Depan Asisten Suara: Semakin Pintar dan Menyatu dalam Kehidupan
Teknologi asisten suara terus berkembang dengan pesat. Di masa depan, kita bisa mengharapkan:
- Pemahaman konteks percakapan yang jauh lebih baik dan kemampuan berdialog multi-giliran yang lebih alami.
- Kemampuan untuk menjadi lebih proaktif, memberikan informasi atau saran bahkan sebelum kita memintanya.
- Integrasi yang lebih mulus dan mendalam dengan berbagai perangkat di sekitar kita (Internet of Things – IoT), mulai dari peralatan rumah tangga hingga mobil.
- Peningkatan dalam aspek privasi dan kontrol pengguna atas data mereka.
Keajaiban Kolaborasi Manusia, AI, dan Cloud
Jadi, setiap kali Anda dengan mudahnya memerintahkan “Hai Google” atau “Halo Siri” untuk melakukan sesuatu, ingatlah bahwa di baliknya ada sebuah “keajaiban” teknologi yang sangat kompleks. Ini adalah hasil kerja keras dari ribuan ilmuwan dan insinyur, yang menggabungkan kekuatan Kecerdasan Buatan (ASR, NLU, NLG, TTS) dengan kapasitas pemrosesan dan penyimpanan data tak terbatas dari server-server pintar di cloud.
Meskipun belum sempurna, asisten suara telah mengubah cara kita berinteraksi dengan teknologi, menjadikannya lebih intuitif, lebih cepat, dan lebih mudah diakses. Dan seiring berjalannya waktu, mereka akan menjadi semakin pintar, semakin memahami kita, dan semakin menyatu dalam setiap aspek kehidupan digital kita.