
Mengenal AWS PVC : Memahami dan Mengenal AWS Data Pipeline
AWS Data Pipeline adalah layanan berbasis web dari Amazon Web Services (AWS) yang memungkinkan pengguna untuk mengotomatiskan proses pemindahan dan transformasi data di seluruh layanan AWS dan sumber data on-premises.
pertimbangan contoh javaTpoint yang berfokus pada konten teknis. Berikut ini adalah tujuan utamanya:
- Meningkatkan konten: Menampilkan konten yang ingin dilihat oleh pelanggan di masa depan. Dengan cara ini, konten dapat ditingkatkan.
- Mengelola aplikasi secara efisien: Melacak semua aktivitas dalam aplikasi dan menyimpan data dalam database yang sudah ada daripada menyimpan data dalam database baru.
- Lebih cepat: Untuk meningkatkan bisnis dengan lebih cepat namun dengan biaya yang lebih murah.
Mencapai tujuan di atas mungkin merupakan tugas yang sulit karena sejumlah besar data disimpan dalam format yang berbeda, sehingga menganalisis, menyimpan, dan memproses data menjadi sangat kompleks. Berbagai alat digunakan untuk menyimpan format data yang berbeda. Solusi yang layak untuk situasi seperti ini adalah dengan menggunakan Data Pipeline. Data Pipeline mengintegrasikan data yang tersebar di berbagai sumber data yang berbeda, dan juga memproses data di lokasi yang sama.
Apa itu Data Pipeline?
AWS Data Pipeline adalah layanan web yang dapat mengakses data dari berbagai layanan dan menganalisis, memproses data di lokasi yang sama, dan kemudian menyimpan data tersebut ke layanan AWS yang berbeda seperti DynamoDB, Amazon S3, dll.
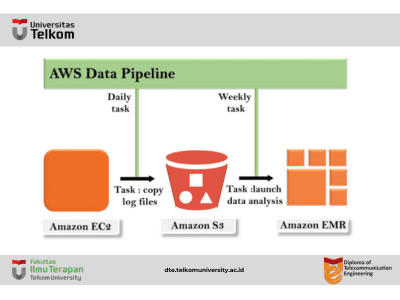
Dengan menggunakan AWS Data Pipeline, data pipeline dapat diatur untuk mengarsipkan log server web ke bucket Amazon S3 setiap hari dan kemudian menjalankan klaster EMR pada log ini yang menghasilkan laporan setiap minggu.
Konsep Data Pipeline
Konsep Data Pipeline AWS sangat sederhana. Kami memiliki Data Pipeline yang berada di bagian atas. Kami memiliki penyimpanan input yang dapat berupa Amazon S3, Dynamo DB, atau Redshift. Data dari penyimpanan input ini dikirim ke Data Pipeline. Data Pipeline menganalisis, memproses data, dan kemudian hasilnya dikirim ke penyimpanan keluaran. Penyimpanan output ini dapat berupa Amazon Redshift, Amazon S3, atau Redshift.
keuntungan Pipa Data AWS
- Easy to Use : AWS Data Pipeline sangat mudah dibuat karena AWS menyediakan konsol seret dan lepas, jadi tidak perlu menulis logika bisnis untuk membuat pipeline data.
- Distributed : Dibangun di atas infrastruktur yang terdistribusi dan dapat diandalkan. Jika terjadi kesalahan dalam aktivitas saat membuat Data Pipeline, maka layanan Data Pipeline AWS akan mencoba kembali aktivitas tersebut.
- Flexible : Data Pipeline juga mendukung berbagai fitur seperti penjadwalan, pelacakan ketergantungan, dan penanganan kesalahan. Data Pipeline dapat melakukan berbagai tindakan seperti menjalankan pekerjaan Amazon EMR, menjalankan Query SQL terhadap database, atau menjalankan aplikasi kustom yang berjalan pada instance EC2.
- Inexpensive : AWS Data Pipeline sangat murah untuk digunakan, dan dibangun dengan tarif bulanan yang rendah.
- Scalabl : Dengan menggunakan Data Pipeline, dapat mengirimkan pekerjaan ke satu atau banyak mesin secara serial maupun paralel.
- Tranparent : AWS Data Pipeline menawarkan kontrol penuh atas sumber daya komputasi seperti instance EC2 atau laporan EMR.
Komponen AWS Data Pipeline
- Pipeline Definition : Definisi ini menentukan bagaimana logika bisnis harus berkomunikasi dengan Data Pipeline. Berisi informasi yang berbeda:
- Data Nodes : Menentukan nama, lokasi, dan format sumber data seperti Amazon S3, Dynamo DB, dll.
- Activities : Aktivitas adalah tindakan yang melakukan Query SQL pada database, mengubah data dari satu sumber data ke sumber data lain.
- Schedules : Penjadwalan dilakukan pada Aktivitas.
- Preconditions : Prasyarat harus dipenuhi sebelum menjadwalkan aktivitas. Misalnya, Anda ingin memindahkan data dari Amazon S3, maka prasyaratnya adalah memeriksa apakah data tersebut tersedia di Amazon S3 atau tidak. Jika prasyarat terpenuhi, maka aktivitas akan dilakukan.
- Resources : Anda memiliki sumber daya komputasi seperti Amazon EC2 atau cluster EMR.
- Actions : Memperbarui status tentang pipeline Anda seperti dengan mengirim email kepada Anda atau memicu alarm.
- Pipeline : Terdiri dari tiga item penting
- Pipeline Components : Kami telah membahas tentang komponen pipeline. Pada dasarnya ini adalah cara untuk mengomunikasikan Data Pipeline Anda ke layanan AWS.
- Instances : Ketika semua komponen pipeline dikompilasi dalam pipeline, maka akan tercipta sebuah instance yang dapat ditindaklanjuti yang berisi informasi tugas tertentu.
- Attempts : Kita tahu bahwa Data Pipeline memungkinkan Anda untuk mencoba kembali operasi yang gagal. Ini tidak lain adalah Attempts.
- Task Runner : Task Runner adalah aplikasi yang mengumpulkan tugas dari Data Pipeline dan menjalankan tugas-tugas tersebut.
Arsitektur Task Runner

Dalam arsitektur di atas, Task Runner melakukan polling tugas dari Data Pipeline. Task Runner melaporkan kemajuannya segera setelah tugas selesai. Setelah pelaporan, dilakukan pengecekan kondisi apakah tugas berhasil atau tidak. Jika suatu tugas berhasil, maka tugas tersebut berakhir dan jika tidak, upaya coba lagi akan dicentang. Jika upaya percobaan ulang masih ada, maka seluruh proses akan dilanjutkan lagi; jika tidak, tugas akan berakhir secara tiba-tiba.