
Data Fabric & Data Mesh: Arsitektur Data Terdesentralisasi untuk Analitik Lincah di Era Hybrid dan Multi-Cloud
Di tengah ledakan volume data dan semakin kompleksnya lanskap teknologi informasi, organisasi modern menghadapi tantangan signifikan dalam mengelola dan memanfaatkan aset data mereka secara efektif. Pendekatan tradisional dengan data warehouse terpusat atau data lake monolitik seringkali kesulitan mengakomodasi kecepatan, skala, dan keragaman data yang dihasilkan di era digital ini. Keterbatasan ini semakin terasa dalam lingkungan hybrid cloud dan multi-cloud, di mana data tersebar di berbagai sistem, baik on-premise maupun di berbagai penyedia layanan cloud. Sebagai respons terhadap tantangan ini, muncullah dua paradigma arsitektur data terdesentralisasi yang menjanjikan: Data Fabric dan Data Mesh. Keduanya bertujuan untuk menyederhanakan akses data, meningkatkan kelincahan analitik, dan memberdayakan tim untuk mengambil keputusan berbasis data dengan lebih cepat, namun dengan pendekatan filosofis dan teknis yang berbeda.
Keterbatasan Arsitektur Data Tradisional di Era Modern
Sebelum menyelami Data Fabric dan Data Mesh, penting untuk memahami mengapa arsitektur data yang lebih tua mulai goyah. Selama beberapa dekade, data warehouse terpusat menjadi andalan untuk business intelligence (BI) dan pelaporan. Kemudian, data lake muncul sebagai solusi untuk menangani volume besar data mentah dalam berbagai format. Meskipun bermanfaat pada masanya, pendekatan terpusat ini seringkali menghadapi kendala:
- Keterlambatan (Latency): Proses ETL (Extract, Transform, Load) atau ELT yang panjang untuk memindahkan dan mempersiapkan data ke sistem terpusat dapat menyebabkan keterlambatan dalam penyediaan data untuk analisis.
- Skalabilitas Terbatas dan Biaya Tinggi: Mempertahankan dan menskalakan sistem data terpusat yang besar bisa menjadi sangat mahal dan kompleks.
- Kurangnya Kelincahan (Agility): Permintaan perubahan atau penambahan sumber data baru seringkali memerlukan upaya rekayasa data yang signifikan dari tim pusat, memperlambat inovasi.
- Ketergantungan pada Tim Pusat: Tim bisnis atau analis seringkali harus bergantung pada tim TI atau data pusat untuk mengakses dan memahami data, menciptakan bottleneck.
- Kesulitan Mengelola Data Terdistribusi: Dalam lingkungan hybrid dan multi-cloud, memusatkan semua data menjadi tidak praktis, mahal, dan terkadang melanggar regulasi kedaulatan data.
- Kurangnya Kepemilikan Data yang Jelas: Ketika data dipusatkan, kepemilikan dan pemahaman kontekstual dari data tersebut seringkali hilang atau menjadi kabur.
Tantangan-tantangan inilah yang mendorong lahirnya pendekatan arsitektur data yang lebih terdesentralisasi, adaptif, dan berorientasi pada layanan mandiri (self-service).
Data Fabric: Menenun Jaringan Data yang Terintegrasi dan Cerdas

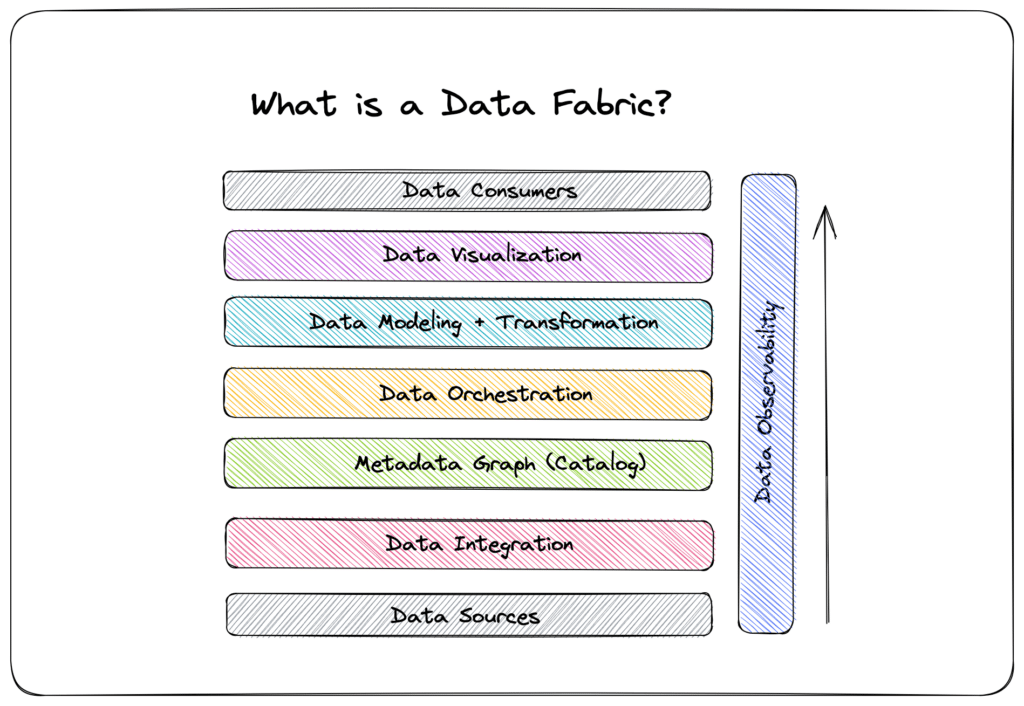
Data Fabric adalah sebuah arsitektur dan serangkaian layanan data yang menyediakan akses data yang konsisten dan terpadu di berbagai lingkungan endpoint yang berbeda, mulai dari on-premise hingga multi-cloud. Alih-alih memindahkan semua data ke satu lokasi fisik, Data Fabric berfokus pada pembuatan lapisan virtual yang menghubungkan sumber-sumber data yang terdistribusi, memungkinkan data ditemukan, diakses, diintegrasikan, dan dibagikan secara lebih efisien.
Prinsip dan Komponen Kunci Data Fabric:
- Katalog Metadata Aktif (Active Metadata Catalog): Ini adalah inti dari Data Fabric. Metadata tidak lagi hanya bersifat pasif (deskriptif), melainkan aktif digunakan untuk mengotomatisasi berbagai aspek pengelolaan data. Ini mencakup metadata teknis, bisnis, operasional, dan sosial.
- Graf Pengetahuan (Knowledge Graph): Seringkali dibangun di atas katalog metadata, graf pengetahuan membantu memahami hubungan antara entitas data, proses bisnis, dan pengguna, memberikan konteks yang lebih kaya.
- Tata Kelola dan Keamanan Terintegrasi: Data Fabric menyematkan kemampuan tata kelola (governance), kepatuhan (compliance), dan keamanan ke dalam arsitekturnya, memastikan data diakses dan digunakan sesuai kebijakan.
- Orkestrasi dan Integrasi Data Cerdas: Memanfaatkan AI/ML untuk mengotomatisasi proses penemuan data, integrasi, transformasi, dan persiapan data. Ini termasuk rekomendasi data, pemetaan skema otomatis, dan deteksi kualitas data.
- Akses Data Universal dan Layanan Mandiri: Menyediakan antarmuka dan alat yang memungkinkan pengguna bisnis dan teknis untuk dengan mudah menemukan, mengakses, dan menggunakan data yang mereka butuhkan, di mana pun data itu berada.
- Persiapan dan Pengiriman Data Otomatis: Mengotomatiskan pipeline data untuk berbagai kasus penggunaan analitik dan operasional.
baca juga: cloud-backup
Bagaimana Data Fabric Bekerja?
Data Fabric tidak selalu mengharuskan pemindahan data secara fisik. Sebaliknya, ia lebih banyak mengandalkan virtualisasi data, API, dan teknik integrasi data modern untuk menyediakan tampilan data yang terpadu. Ketika seorang pengguna atau aplikasi meminta data, Data Fabric, melalui katalog metadatanya dan mesin orkestrasinya, akan menentukan lokasi data tersebut, menerapkan transformasi yang diperlukan secara on-the-fly (jika memungkinkan dan efisien), dan mengirimkannya ke konsumen. Ia juga dapat mengoptimalkan penempatan data atau merekomendasikan pemindahan data jika diperlukan untuk kinerja.
Tujuan Utama Data Fabric:
- Menyederhanakan dan mengotomatisasi akses ke data yang terdistribusi.
- Meningkatkan produktivitas pengguna data.
- Mempercepat waktu untuk mendapatkan insight.
- Memastikan tata kelola data yang konsisten di seluruh lanskap data.
Data Fabric seringkali dilihat sebagai evolusi dari platform integrasi data tradisional, yang diperkaya dengan kemampuan AI/ML dan fokus pada otomatisasi pengelolaan metadata.
Data Mesh: Demokratisasi Data Melalui Kepemilikan Terdesentralisasi

Data Mesh adalah pendekatan arsitektur data terdesentralisasi yang berfokus pada aspek sosio-teknis. Ia menggeser tanggung jawab atas data dari tim pusat ke tim domain bisnis yang paling dekat dengan data tersebut dan paling memahaminya. Data Mesh menganjurkan perubahan organisasi dan budaya selain perubahan teknis.
Konsep ini diperkenalkan oleh Zhamak Dehghani dan didasarkan pada empat prinsip utama:
- Kepemilikan Data Berorientasi Domain (Domain-Oriented Decentralized Data Ownership and Architecture):
- Data dimiliki dan dikelola oleh tim domain bisnis yang menghasilkan atau paling banyak menggunakan data tersebut (misalnya, tim pemasaran memiliki data kampanye, tim penjualan memiliki data pelanggan).
- Arsitektur data dipecah berdasarkan domain ini, dengan setiap domain bertanggung jawab atas pipeline data dan kualitas data mereka sendiri.
- Data sebagai Produk (Data as a Product):
- Setiap domain memperlakukan data mereka sebagai produk yang mereka tawarkan kepada konsumen data lain di dalam organisasi (tim analitik, ilmuwan data, domain lain).
- “Produk data” ini harus memiliki kualitas tinggi, mudah ditemukan, dapat dipahami, dapat diakses, aman, dapat dioperasikan (interoperable), dan dapat dipercaya. Ini berarti adanya dokumentasi yang jelas, Service Level Objectives (SLOs), dan pemilik produk data yang bertanggung jawab.
- Infrastruktur Data Layanan Mandiri sebagai Platform (Self-Serve Data Infrastructure as a Platform):
- Untuk memungkinkan tim domain mengelola produk data mereka secara mandiri, platform infrastruktur data pusat menyediakan alat, layanan, dan kemampuan self-service.
- Tim domain tidak perlu membangun semuanya dari awal, melainkan dapat memanfaatkan platform ini untuk membuat, men-deploy, memantau, dan mengelola produk data mereka. Ini mencakup penyimpanan, pemrosesan, pipeline, keamanan, dan pemantauan.
- Tata Kelola Komputasional Terfederasi (Federated Computational Governance):
- Meskipun kepemilikan data terdesentralisasi, standar global, kebijakan, dan interoperabilitas tetap penting.
- Model tata kelola terfederasi dibentuk dengan perwakilan dari tim domain dan tim platform pusat. Kelompok ini mendefinisikan standar global (misalnya, untuk keamanan, kualitas data, interoperabilitas) yang kemudian diotomatisasi dan diimplementasikan sebagai bagian dari platform self-service. Tujuannya adalah mencapai keseimbangan antara otonomi domain dan standar global.
Bagaimana Data Mesh Bekerja?
Dalam Data Mesh, setiap domain bisnis bertanggung jawab penuh atas siklus hidup data mereka, mulai dari ingestion, pembersihan, transformasi, hingga penyajiannya sebagai produk data yang siap pakai. Konsumen data dari domain lain dapat menemukan dan mengakses produk data ini melalui platform data self-service, dengan jaminan kualitas dan pemahaman yang disediakan oleh domain pemilik. Tata kelola memastikan bahwa semua produk data mematuhi standar organisasi.
Tujuan Utama Data Mesh:
- Meningkatkan kelincahan dan skalabilitas analitik dengan mendistribusikan tanggung jawab.
- Meningkatkan kualitas dan pemahaman data dengan menempatkan kepemilikan pada ahli domain.
- Mengurangi bottleneck pada tim data pusat.
- Memberdayakan tim domain untuk berinovasi dengan data mereka.
Data Mesh menekankan perubahan paradigma dari data sebagai aset yang dikelola secara terpusat menjadi data sebagai produk yang dikelola secara terdistribusi oleh domain yang relevan.
Data Fabric vs. Data Mesh: Perbedaan, Persamaan, dan Sinergi

{kind=link}
{kind=link}
Meskipun keduanya bertujuan untuk mengatasi tantangan data modern, Data Fabric dan Data Mesh memiliki perbedaan fundamental:
| Aspek | Data Fabric | Data Mesh |
|---|---|---|
| Fokus Utama | Integrasi data teknis dan akses data terpadu melalui otomatisasi metadata. | Perubahan organisasi dan budaya menuju kepemilikan data terdesentralisasi oleh domain. |
| Penggerak Utama | Teknologi (metadata, AI/ML, integrasi data). | Organisasi dan Manusia (kepemilikan domain, data sebagai produk). |
| Kepemilikan Data | Cenderung tetap terpusat atau hibrid, dengan Fabric sebagai lapisan integrasi. | Terdesentralisasi penuh ke tim domain bisnis. |
| Data sebagai Produk | Kurang ditekankan secara eksplisit, meskipun Fabric dapat mendukungnya. | Prinsip inti dan fundamental. |
| Perubahan Organisasi | Lebih sedikit memerlukan perubahan organisasi yang drastis. | Memerlukan perubahan budaya dan struktur organisasi yang signifikan. |
| Implementasi | Lebih berfokus pada implementasi platform teknologi. | Kombinasi antara perubahan organisasi, budaya, dan platform teknologi pendukung. |
| Tata Kelola | Cenderung lebih terpusat, diimplementasikan melalui Fabric. | Terfederasi, dengan partisipasi aktif dari domain. |
| Arsitektur Data | Menciptakan lapisan konektivitas dan akses data di atas infrastruktur yang ada. | Mendorong arsitektur data yang terdistribusi secara fisik dan logis berdasarkan domain. |
| Fleksibilitas Sumber Data | Sangat fleksibel dalam menghubungkan berbagai sumber data. | Fleksibel, tetapi setiap domain mengelola sumber datanya sendiri sebagai produk. |
Persamaan:
- Keduanya bertujuan untuk menyederhanakan akses data di lingkungan yang kompleks.
- Keduanya mengakui pentingnya metadata.
- Keduanya berusaha untuk memberdayakan lebih banyak pengguna data.
- Keduanya relevan untuk lingkungan hybrid dan multi-cloud.
Sinergi Potensial:
Data Fabric dan Data Mesh tidak selalu harus dilihat sebagai pilihan yang saling eksklusif. Dalam beberapa skenario, keduanya bisa saling melengkapi:
- Data Fabric dapat menyediakan kemampuan teknologi (seperti katalog metadata aktif dan alat integrasi data cerdas) yang mendukung implementasi platform infrastruktur data self-service dalam arsitektur Data Mesh.
- Prinsip “data sebagai produk” dari Data Mesh dapat diadopsi dalam konteks Data Fabric untuk meningkatkan kualitas dan kegunaan layanan data yang disediakan oleh Fabric.
- Data Mesh dapat menyediakan kerangka kerja organisasi dan tata kelola untuk data yang diintegrasikan dan dikelola oleh Data Fabric.
Pilihan antara Data Fabric, Data Mesh, atau kombinasi keduanya akan sangat bergantung pada konteks spesifik organisasi, budaya, kematangan data, dan tujuan strategis.
baca juga: password-manager-solusi-atau-ancaman-baru
Memberdayakan Analitik Lincah di Era Hybrid dan Multi-Cloud
Baik Data Fabric maupun Data Mesh menawarkan jalur menuju analitik yang lebih lincah, terutama dalam lanskap hybrid dan multi-cloud yang kompleks:
- Akses Data yang Disederhanakan dan Dipercepat:
- Data Fabric: Menyediakan lapisan akses terpadu yang menyembunyikan kompleksitas lokasi fisik data. Analis dapat menemukan dan mengakses data dari berbagai sistem cloud dan on-premise melalui satu titik interaksi.
- Data Mesh: Dengan “produk data” yang jelas dan dapat ditemukan, analis dapat dengan mudah mengakses data berkualitas tinggi yang relevan dengan domain mereka atau domain lain tanpa melalui bottleneck pusat.
- Kemampuan Layanan Mandiri (Self-Service):
- Data Fabric: Seringkali menyertakan alat dan antarmuka self-service yang didukung oleh metadata aktif, memungkinkan pengguna untuk menjelajahi dan mempersiapkan data sendiri.
- Data Mesh: Prinsip infrastruktur data self-service adalah inti, memberdayakan tim domain untuk mengelola data mereka dan tim analitik untuk mengonsumsi produk data secara mandiri.
- Peningkatan Kolaborasi Lintas Tim:
- Data Fabric: Dengan metadata yang diperkaya dan graf pengetahuan, pemahaman data bersama dapat ditingkatkan.
- Data Mesh: Struktur domain dan konsep “data sebagai produk” mendorong komunikasi dan kolaborasi yang lebih baik antara produsen data (domain) dan konsumen data (analis, ilmuwan data).
- Skalabilitas untuk Pertumbuhan Data dan Analitik:
- Data Fabric: Dapat menskalakan kemampuan integrasi dan pengiriman datanya seiring pertumbuhan sumber data.
- Data Mesh: Desain terdesentralisasi secara inheren lebih mudah diskalakan. Setiap domain dapat menskalakan produk datanya secara independen.
- Dukungan untuk Beragam Alat Analitik: Kedua arsitektur ini dirancang untuk menyediakan data ke berbagai alat analitik dan BI, memungkinkan tim untuk menggunakan alat terbaik untuk pekerjaan mereka.
- Tata Kelola yang Adaptif untuk Lingkungan Terdistribusi:
- Data Fabric: Memungkinkan penerapan kebijakan tata kelola secara konsisten di seluruh data yang terhubung.
- Data Mesh: Model tata kelola komputasional terfederasi memungkinkan keseimbangan antara otonomi domain dan standar global, yang penting dalam lingkungan hybrid dan multi-cloud yang kompleks.
- Mengurangi Ketergantungan pada Lokasi Fisik Data: Keduanya membantu mengabstraksi lokasi fisik data, memungkinkan organisasi untuk memanfaatkan manfaat dari berbagai penyedia cloud dan sistem on-premise tanpa terjebak dalam silo data.
Dengan mengatasi gesekan dalam akses dan penggunaan data, Data Fabric dan Data Mesh secara signifikan dapat mengurangi waktu siklus dari pertanyaan ke insight, yang merupakan inti dari analitik lincah.
Manfaat dan Tantangan Implementasi
Manfaat Utama (Umum untuk Keduanya, dengan Penekanan Berbeda):
- Peningkatan Kelincahan Bisnis: Respons lebih cepat terhadap perubahan pasar dan peluang baru.
- Demokratisasi Data: Lebih banyak orang dapat mengakses dan menggunakan data dengan aman.
- Peningkatan Kualitas Data: Terutama ditekankan dalam Data Mesh melalui kepemilikan domain dan “data sebagai produk”.
- Pengurangan Silo Data: Memfasilitasi aliran data lintas departemen dan sistem.
- Tata Kelola dan Kepatuhan yang Lebih Baik: Meskipun dengan pendekatan yang berbeda (terpusat vs. terfederasi).
- Optimalisasi Biaya: Dengan mengurangi duplikasi data (lebih pada Fabric) dan memberdayakan tim (lebih pada Mesh).
- Inovasi yang Didorong Data: Mendorong eksperimen dan pengembangan produk berbasis data.
Tantangan Implementasi:
- Kompleksitas Teknologi: Membangun Data Fabric atau platform pendukung Data Mesh memerlukan teknologi canggih dan integrasi yang kompleks.
- Perubahan Budaya dan Organisasi (Terutama untuk Data Mesh): Menggeser kepemilikan data, menumbuhkan budaya “data sebagai produk”, dan mengubah cara tim bekerja adalah tantangan besar.
- Kesenjangan Keterampilan: Membutuhkan keahlian baru dalam rekayasa data, arsitektur data, pengelolaan produk data, dan tata kelola terdistribusi.
- Tata Kelola Terdesentralisasi yang Efektif: Merancang dan menerapkan model tata kelola terfederasi yang berfungsi dengan baik dalam Data Mesh memerlukan upaya yang signifikan.
- Manajemen Metadata: Memastikan metadata akurat, lengkap, dan aktif adalah krusial namun menantang.
- Biaya Awal: Investasi awal dalam teknologi dan perubahan proses bisa jadi signifikan.
- Memulai dari yang Sudah Ada (Brownfield): Menerapkan konsep ini pada lanskap data legacy yang sudah kompleks bisa lebih sulit daripada memulai dari awal (greenfield).
Memilih Arsitektur Data untuk Masa Depan Analitik
Data Fabric dan Data Mesh mewakili pergeseran paradigma penting dalam cara organisasi mendekati arsitektur dan pengelolaan data. Keduanya menawarkan solusi untuk mengatasi keterbatasan pendekatan terpusat tradisional, terutama dalam menghadapi kompleksitas lingkungan hybrid dan multi-cloud serta tuntutan akan analitik yang semakin lincah.
Data Fabric menawarkan jalur evolusioner, berfokus pada integrasi data yang cerdas dan otomatisasi melalui teknologi metadata canggih untuk menyatukan lanskap data yang terfragmentasi. Ini bisa menjadi pilihan yang baik untuk organisasi yang ingin meningkatkan akses dan integrasi data tanpa melakukan perubahan organisasi yang drastis.
Data Mesh, di sisi lain, adalah pendekatan yang lebih transformasional, menekankan perubahan sosio-teknis dengan mendesentralisasikan kepemilikan data ke domain bisnis dan memperlakukan data sebagai produk. Ini sangat cocok untuk organisasi besar dan kompleks yang ingin mencapai skalabilitas dan kelincahan tim yang tinggi, serta siap untuk merangkul perubahan budaya yang signifikan.
Pilihan antara keduanya, atau bahkan kombinasi elemen dari keduanya, akan bergantung pada kebutuhan unik, kematangan, budaya, dan tujuan strategis setiap organisasi. Namun, yang jelas adalah bahwa masa depan pengelolaan data terletak pada pendekatan yang lebih terdistribusi, cerdas, dan berorientasi pada layanan mandiri. Dengan merangkul prinsip-prinsip di balik Data Fabric dan Data Mesh, organisasi dapat membangun fondasi data yang kuat dan adaptif, siap untuk mendorong inovasi dan keunggulan kompetitif di era data yang terus berkembang.