Jaringan Anti Mati: Cara Membuat Sistem Komputer yang Kuat dengan FHRP
Di dunia digital yang sangat bersaing saat ini, jaringan yang selalu aktif itu penting banget buat keberhasilan sebuah organisasi. Jaringan mati sebentar saja bisa bikin rugi besar, bikin karyawan nggak produktif, bahkan merusak nama baik perusahaan. Makanya, punya sistem cadangan (redundansi) yang kuat bukan lagi pilihan, tapi wajib ada di infrastruktur IT modern.
Memahami Dasar-dasar Redundansi Jaringan
Redundansi jaringan adalah strategi untuk menduplikasi bagian-bagian penting di jaringan. Intinya, setiap komponen punya kemungkinan untuk rusak. Jadi, dengan menyediakan komponen cadangan, sistem bisa tetap jalan normal meskipun ada bagian utama yang rusak.
Berbeda dengan sistem tunggal yang gampang banget mati kalau ada satu bagiannya yang rusak (single point of failure), arsitektur dengan redundansi punya banyak jalur dan mekanisme failover (pengalihan otomatis) yang bisa langsung mengambil alih fungsi saat komponen utama bermasalah. Dengan pengaturan yang tepat, sistem bisa mencapai tingkat ketersediaan hingga 99.99% atau lebih tinggi, yang sering disebut “empat sembilan” (four nines) dalam industri.
Macam-macam Redundansi dalam Infrastruktur Jaringan
Redundansi bisa diterapkan di berbagai lapisan:
1. Redundansi Perangkat Keras (Hardware)
Ini adalah lapisan pertama. Kita menduplikasi perangkat keras penting seperti banyak router dan switch dalam satu topologi. Jadi, kalau satu perangkat rusak, lalu lintas data bisa otomatis dialihkan ke perangkat cadangan tanpa mengganggu layanan.
Redundansi hardware juga mencakup penggunaan komponen yang bisa langsung diganti tanpa mematikan sistem (hot-swap), seperti dua power supply (cadangan), modul kipas, dan kartu interface. Dengan desain ini, perawatan dan penggantian komponen bisa dilakukan tanpa mematikan seluruh sistem.
2. Redundansi Pasokan Listrik
Kestabilan pasokan listrik adalah pondasi sistem redundan yang andal. Menggunakan UPS (Uninterruptible Power Supply) dengan kapasitas yang cukup, ditambah dengan generator cadangan untuk pemadaman listrik yang lebih lama, memastikan perangkat jaringan bisa terus beroperasi meskipun ada gangguan listrik.
Pusat data modern juga sering memakai dua jalur listrik dari perusahaan listrik yang berbeda. Jadi, jika satu jaringan listrik bermasalah, pasokan listrik alternatif bisa langsung mengambil alih. Sistem pemantauan konsumsi listrik dan kesehatan baterai juga penting.
3. Redundansi Server dan Aplikasi
Redundansi server melibatkan clustering (menggabungkan beberapa server jadi satu unit) dan load balancing (membagi beban kerja) untuk memastikan aplikasi penting tetap bisa diakses meskipun salah satu server mati. Teknologi virtualisasi memungkinkan pembuatan cluster yang sangat tersedia, di mana mesin virtual bisa dipindahkan secara langsung (live migration) jika server induk perlu perawatan.
Platform pengaturan container seperti Kubernetes menyediakan fitur redundansi bawaan seperti replica set dan penjadwalan pod otomatis, yang memungkinkan aplikasi “menyembuhkan diri” (self-heal) jika ada container atau node yang gagal.
4. Redundansi Jalur dan Agregasi Link
Mendiversifikasi jalur komunikasi melalui banyak kabel fisik dan koneksi independen dari penyedia layanan memastikan komunikasi tetap berjalan meskipun ada kabel putus atau gangguan pada penyedia layanan. Protokol agregasi link seperti LACP (Link Aggregation Control Protocol) memungkinkan penggabungan beberapa koneksi menjadi satu interface logis dengan kecepatan yang lebih tinggi dan kemampuan failover bawaan.
Penerapan jalur routing yang beragam juga melibatkan pemisahan geografis. Artinya, jalur utama dan cadangan menggunakan rute fisik yang berbeda untuk menghindari single point of failure akibat kecelakaan konstruksi atau bencana alam.
5. Redundansi Data dan Sistem Penyimpanan
Redundansi penyimpanan melalui teknologi RAID (Redundant Array of Independent Disks) memberikan perlindungan terhadap kerusakan disk dengan menyebarkan data ke banyak drive. Konfigurasi RAID yang berbeda menawarkan kompromi antara kinerja, kapasitas, dan toleransi kesalahan sesuai kebutuhan aplikasi.
Sistem penyimpanan modern juga menerapkan teknologi snapshot dan replikasi yang memungkinkan pemulihan data pada titik waktu tertentu dan pemulihan bencana geografis. Solusi cadangan berbasis cloud memberikan lapisan perlindungan tambahan dengan penyimpanan data di luar lokasi.
Cara Kerja Sistem Redundansi
Sistem redundan bekerja dengan memantau terus-menerus dan membuat keputusan otomatis untuk mendeteksi kegagalan dan melakukan failover. Mekanisme pengecekan kesehatan menggunakan sinyal heartbeat, pesan keepalive, dan metrik kinerja untuk mengevaluasi status komponen secara real-time.
Ketika kegagalan terdeteksi, algoritma failover akan mengevaluasi sumber daya cadangan yang tersedia dan mengalihkan lalu lintas data dengan gangguan layanan minimal. Sistem canggih bahkan bisa melakukan failover prediktif berdasarkan indikator kinerja yang menurun sebelum kegagalan nyata terjadi.
Keuntungan Menerapkan Redundansi
- Peningkatan Keberlanjutan Bisnis: Redundansi yang dirancang dengan baik bisa mengurangi waktu mati yang direncanakan dan tidak direncanakan secara signifikan, memungkinkan organisasi menjaga kelangsungan operasional bisnis. Ini sangat penting untuk industri seperti keuangan, kesehatan, dan e-commerce yang butuh ketersediaan 24/7.
- Optimasi Jendela Perawatan (Maintenance Window): Dengan komponen yang redundan, aktivitas pemeliharaan bisa dilakukan tanpa mengganggu layanan. Strategi pemeliharaan bergulir memungkinkan pembaruan dan peningkatan sistem secara bertahap tanpa memengaruhi pengalaman pengguna akhir.
- Peningkatan Kinerja dan Distribusi Beban: Sistem redundan bisa diatur untuk load balancing, yaitu membagi lalu lintas data ke banyak sumber daya untuk optimasi kinerja. Ini juga mencegah kemacetan sumber daya dan memungkinkan pemanfaatan infrastruktur yang lebih baik.
- Peningkatan Kemampuan Pemulihan Bencana (Disaster Recovery): Redundansi geografis memberikan perlindungan terhadap bencana lokal dan memungkinkan pemulihan cepat dari peristiwa besar. Cadangan situs jarak jauh bisa diaktifkan untuk menjaga operasional bisnis saat fasilitas utama bermasalah.
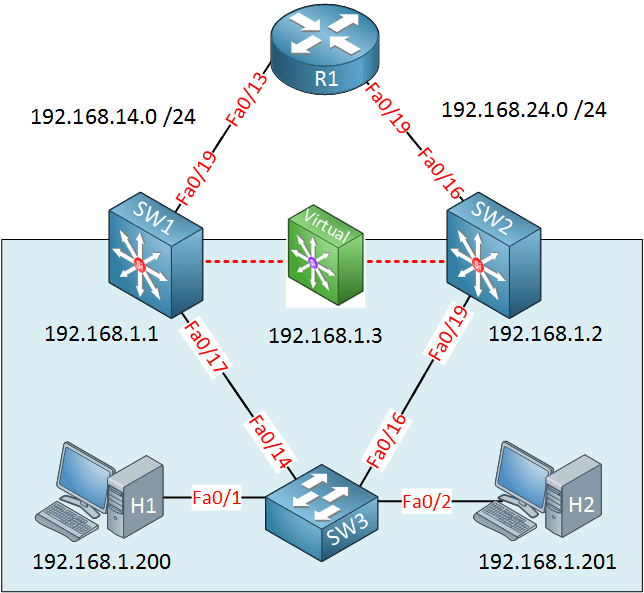
First Hop Redundancy Protocol (FHRP): Solusi Lengkap untuk Cadangan Gateway
First Hop Redundancy Protocol (FHRP) adalah teknologi dasar yang menyediakan pengalihan otomatis untuk default gateway dalam infrastruktur jaringan. Protokol ini mengatasi masalah single point of failure di lapisan jaringan dengan menggunakan alamat IP virtual dan alamat MAC virtual yang dibagikan antar beberapa router.
Dalam penerapan FHRP, perangkat akhir (komputer pengguna) diatur dengan alamat gateway virtual. Sementara itu, beberapa router fisik bekerja secara terkoordinasi untuk menyediakan layanan gateway. Ketika router utama (active router) gagal, router cadangan (standby router) akan secara mulus mengambil alih fungsi gateway tanpa perlu konfigurasi ulang pada perangkat klien.
a. Hot Standby Router Protocol (HSRP): Solusi Khusus Cisco
HSRP adalah protokol milik Cisco yang terbukti andal di lingkungan produksi. Protokol ini menggunakan mekanisme pemilihan berbasis prioritas untuk menentukan router aktif dan siaga dalam grup HSRP.
Konfigurasi HSRP melibatkan penetapan alamat IP virtual yang akan digunakan sebagai default gateway oleh perangkat akhir. Router aktif akan merespons permintaan ARP untuk alamat IP virtual, sementara router siaga akan memantau status router aktif melalui pertukaran paket hello. Ketika kegagalan router aktif terdeteksi, router siaga akan mengambil alih peran aktif dan mulai merespons alamat IP virtual. Proses ini biasanya terjadi dalam beberapa detik, meminimalkan gangguan layanan bagi pengguna akhir.
Keunggulan HSRP:
HSRP menyediakan implementasi yang matang dan stabil dengan dokumentasi yang luas dan dukungan komunitas. Protokol ini telah dioptimalkan untuk lingkungan Cisco dan terintegrasi dengan baik dengan fitur lain seperti VLAN dan protokol routing. Fitur HSRP canggih seperti object tracking memungkinkan failover berdasarkan kondisi selain kegagalan router, seperti kegagalan link upstream atau status interface tertentu. Ini memberikan kontrol yang lebih rinci terhadap perilaku failover.
b. Virtual Router Redundancy Protocol (VRRP): Pendekatan Standar Industri
VRRP adalah protokol standar terbuka yang didefinisikan dalam RFC 3768, sehingga membuatnya netral terhadap vendor dan dapat diimplementasikan pada peralatan dari berbagai produsen. Protokol ini menyediakan fungsionalitas yang mirip dengan HSRP tetapi dengan beberapa perbedaan dalam detail implementasi.
Salah satu perbedaan signifikan adalah bahwa VRRP menggunakan preemption secara default, di mana router dengan prioritas tertinggi akan secara otomatis mengambil alih peran aktif ketika menjadi tersedia. Ini berbeda dengan HSRP di mana preemption harus dikonfigurasi secara eksplisit.
Fleksibilitas VRRP:
VRRP memberikan fleksibilitas dalam lingkungan multi-vendor dan sering dipilih untuk penerapan yang memerlukan interoperabilitas antara peralatan dari vendor yang berbeda. Protokol ini juga memiliki beban kerja yang relatif rendah dan waktu konvergensi yang cepat.
c. Gateway Load Balancing Protocol (GLBP): Distribusi Beban Lanjutan
GLBP adalah peningkatan dari FHRP tradisional yang tidak hanya menyediakan redundansi tetapi juga kemampuan load balancing. Berbeda dengan HSRP dan VRRP yang hanya menggunakan satu router aktif, GLBP memungkinkan beberapa router untuk secara bersamaan meneruskan lalu lintas data.
Protokol ini menggunakan konsep Active Virtual Gateway (AVG) yang bertanggung jawab untuk respons ARP dan penetapan alamat MAC, serta Active Virtual Forwarder (AVF) yang melakukan penerusan paket aktual. Dengan arsitektur ini, GLBP dapat mendistribusikan beban lalu lintas data ke banyak router untuk pemanfaatan sumber daya yang lebih baik.
Implementasi GLBP di Lingkungan Produksi:
GLBP sangat bermanfaat di lingkungan dengan volume lalu lintas data yang tinggi di mana satu router mungkin menjadi hambatan. Algoritma load balancing dapat dikonfigurasi untuk round-robin, berbasis bobot (weighted), atau distribusi berdasarkan host sesuai dengan kebutuhan spesifik.
Praktik Implementasi
Pertimbangan Desain
Penerapan redundansi yang efektif memerlukan perencanaan yang cermat dan pertimbangan berbagai faktor seperti biaya, kerumitan, dan persyaratan ketersediaan spesifik. Penilaian risiko harus dilakukan untuk mengidentifikasi komponen penting dan skenario kegagalan potensial. Desain topologi jaringan harus mempertimbangkan jalur redundan dan menghindari single point of failure di setiap lapisan. Pemisahan fisik komponen redundan juga penting untuk perlindungan terhadap bahaya lingkungan.
Manajemen Konfigurasi
Konfigurasi yang konsisten antara komponen utama dan cadangan sangat penting untuk failover yang mulus. Alat manajemen konfigurasi dan otomatisasi dapat membantu menjaga sinkronisasi dan mengurangi kesalahan manusia. Pengujian dan validasi rutin mekanisme failover juga penting untuk memastikan redundansi akan berfungsi saat dibutuhkan. Jendela perawatan terjadwal dapat digunakan untuk pengujian failover terkontrol.
Pemantauan dan Pemecahan Masalah
Sistem pemantauan yang komprehensif harus diimplementasikan untuk memberikan visibilitas ke status redundansi dan mendeteksi potensi masalah sebelum menjadi kritis. Mekanisme peringatan harus dikonfigurasi untuk memberi tahu administrator ketika redundansi terganggu. Dokumentasi rinci tentang arsitektur redundansi dan prosedur pemecahan masalah juga penting untuk penyelesaian masalah yang cepat ketika insiden terjadi.
Kesimpulan
Penerapan redundansi jaringan yang komprehensif merupakan investasi penting yang dapat menghindarkan organisasi dari downtime yang mahal dan gangguan layanan. Kombinasi redundansi hardware, failover tingkat protokol, dan pemantauan yang tepat dapat menyediakan infrastruktur jaringan berketersediaan tinggi yang andal.
Pemilihan FHRP yang tepat harus didasarkan pada kebutuhan spesifik, infrastruktur yang ada, dan kebutuhan skalabilitas di masa depan. HSRP cocok untuk lingkungan yang didominasi Cisco, VRRP untuk penerapan multi-vendor, dan GLBP untuk skenario yang memerlukan kemampuan load balancing.
Keberhasilan implementasi redundansi memerlukan pendekatan holistik yang mencakup implementasi teknis, prosedur operasional, dan pengujian rutin. Dengan perencanaan dan pelaksanaan yang tepat, organisasi dapat mencapai ketahanan infrastruktur yang mendukung kelangsungan bisnis dan keunggulan kompetitif dalam ekonomi digital yang dinamis.